这张图可以清晰的看出,BlockStorage的两部分功能分别在NameNode和DataNode中完成。在原来的单NameNode架构中,一个NameNode对应一个Namespace,对应多个DataNode组成的存储池空间,实现和理解起来非常容易。但是随着单NameNode遇到越来越多的问题,例如随着集群规模的请看如下
这张图可以清晰的看出,BlockStorage的两部分功能分别在NameNode和DataNode中完成。在原来的单NameNode架构中,一个NameNode对应一个Namespace,对应多个DataNode组成的存储池空间,实现和理解起来非常容易。但是随着单NameNode遇到越来越多的问题,例如随着集群规模的扩大NameNode的内存已不能容纳所有的元数据;单NameNode制约文件元数据操作的吞吐量使得目前的只能支持60K的MapReducetask;还有就是不同用户的隔离性问题。
那么社区为什么会选择NameNodefederation这种方案呢?因为从系统设计的角度看,ceph的动态分区看起来更适合分布式NameNode的需求。这里就不得不说在系统领域学术界和工业界的区别了。Ceph的设计固然比较先进,但是稳定性非常不好。而对于一个像Hadoop这样规模的存储系统,稳定性固然非常重要,而且开发成本和兼容性也要考虑。NameNodefederation这个方案对代码的改动大部分是在DataNode这块,对NameNode的改动很小。这使得NameNode的鲁棒性不会受到影响,同时也兼容原来的版本。
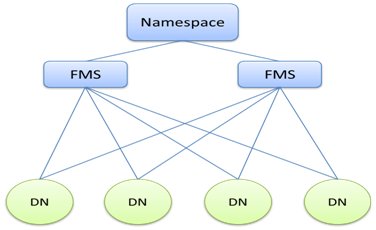
在工业界也有几种其他的分布式NameNode的实现方式,例如在百度内部使用的就是把NameNode做成一主多从的集群的形式,结构如下图所示。Namespaceserver负责整个集群的文件?à唯一的块集合ID映射,然后把不同的块集合ID分配到对应的FMSserver上(类似于数据库里的sharding,可以采用hash类似的策略)。然后每个FMSserver负责一部分块集合的管理和操作。那么这种方法显然client的每次文件操作都会经过Namespaceserver和其中的一个FMSserver的处理。具体是怎么做的,百度也没开源出来。

Federation中存在多个命名空间,如何划分和管理这些命名空间非常关键。例如查看某个目录下面的文件,如果采用文件名hash的方法存放文件,则这些文件可能被放到不同namespace中,HDFS需要访问所有namespace,代价过大。为了方便管理多个命名空间,HDFSNameNodeFederation采用了经典的ClientSideMountTable。
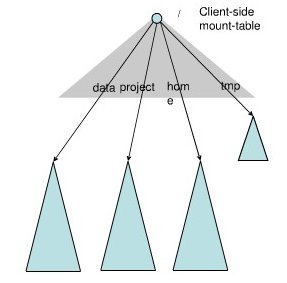
如上图所示,下面四个蓝色三角形代表一个的Namespace,上方灰色的三角形代表从客户角度去访问的逻辑Namespace。各个蓝色的Namespacemount到灰色的表中,客户可以通过访问不同的挂载点来访问不同的namespace,这就如同在Linux系统中访问不同挂载点的磁盘一样。这就是HDFSNameNodeFederation中命名空间管理的基本原理。但是这种方式容易造成不同Namespace下文件数量和存储量的不均衡,需要人工介入已达到理想的负载均衡。
HDFSNameNodeFederation并没有完全解决单点故障问题。虽然namenode/namespace存在多个,但是从单个namenode/namespace看,仍然存在单点故障:如果某个namenode挂掉了,其管理的相应的文件就不可以访问。所以对于其中的任何一个namenode依然存在SPOF问题,而这个问题的解决要依赖于HA的实现。就是给每个NameNode配备一个对应的BackupNode和CheckpointNode。
2,编译源代码
192.168.1.12注:如果你只关注怎么安装和使用,对Hadoop的源代码编译不是很感兴趣,可以直接从官网上download安装包,然后跳过这一节,直接进入第二节:安装与部署。
先从SVN中checkout代码,我checkout的是trunk中的代码。据说trunk中的代码merge了ha-branch,具体都merge了哪些jira讨论的东西没仔细看。
下图就是Checkout出的代码结构。这个和以前的版本源代码结构有很大的不同。整个项目采用maven作为项目管理工具。我对maven也是新手,不过BUILDING.txt会告诉我们大部分想要知道的东西。
tags:192.168.1.12